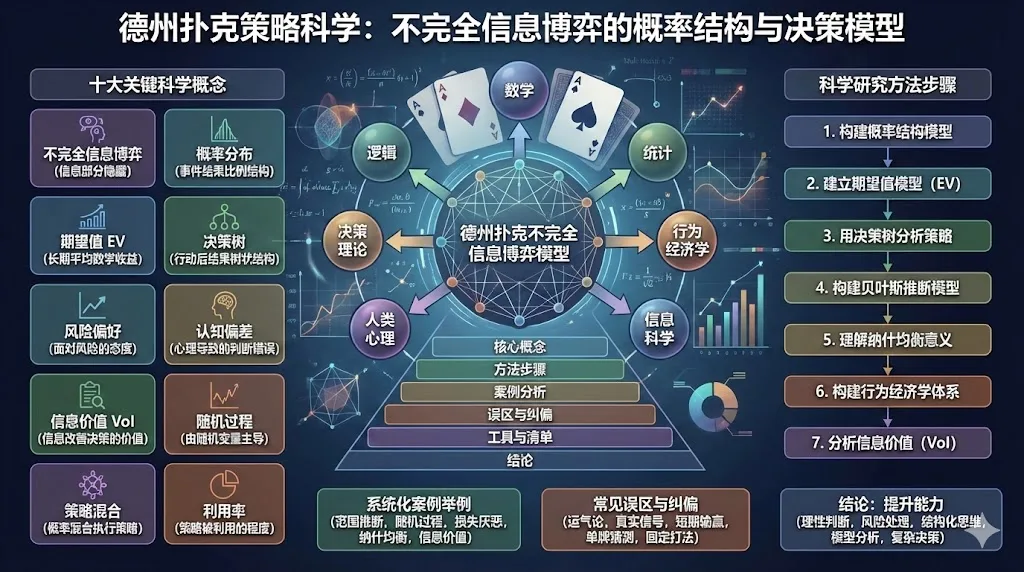
德州扑克(Texas Hold’em)是现代博弈论研究中最具代表性的“不完全信息博弈”模型之一。它的数学结构复杂、心理因素显著、信息差异巨大、策略选择极多,因此被广泛用于研究:
-
概率论的现实应用
-
风险决策模型
-
人类行为偏差
-
人工智能对抗算法
-
有限信息下的推断机制
-
复杂系统的长期均衡特性
德州扑克虽被大众视为一种竞技游戏,但在学术领域,它与围棋、象棋、双陆棋一样,是研究决策科学的重要实验平台。其关键特性包括:
-
信息不完全:玩家无法看到对手底牌
-
决策序列性强:每轮行动形成新信息
-
概率结构复杂:公共牌组合数量巨大
-
对抗性高:每条行动路径都受他人影响
-
行为心理浓厚:损失厌恶、确认偏误、风险偏好
-
可量化但不可完全求解
它既不是纯数学游戏,也不是纯心理游戏,而是一个融合:
-
数学
-
逻辑
-
统计
-
行为经济学
-
信息科学
-
决策理论
-
博弈论
-
人类心理
的综合体系。
这篇文章将从“科学研究”的角度,而非“实战技巧”的角度来系统性分析德州扑克,让读者理解它为何被学界视为一个重要模型,而非仅仅是牌桌上的娱乐。
核心概念
以下列出本篇所用的十个关键科学概念,并在首次出现时给出“定义 + 落地判断”结构。
1. 不完全信息博弈(Incomplete Information Game)
定义:
参与者无法看到所有信息,必须依赖推断和概率判断做出策略选择的博弈。
落地判断:
-
德扑中对手底牌不可见
-
公共牌逐渐揭示信息
-
决策依赖不完整数据而非确定性
动作项:
记录每一轮新出现的信息,以构建更准确的推断模型。
2. 概率分布(Probability Distribution)
定义:
事件所有可能结果的出现概率集合。
落地判断:
-
每张牌的出现概率可以精确计算
-
公牌组合呈高维数据结构
-
人类直觉往往错误估计概率
动作项:
建立基本概率表(例如成牌概率、剩余牌结构等)。
3. 期望值(Expected Value, EV)
定义:
在大量重复中,每次决策的平均数学收益。
落地判断:
-
期望值不是“下一局”结果
-
是长期趋向
-
所有策略可视为 EV 模型
动作项:
将每个行动转化为 EV 参数化模型。
4. 决策树(Decision Tree)
定义:
一个决策会导致多个未来路径,每个路径的收益与概率不同。
落地判断:
-
德扑每一步都有分叉
-
最优选择等于最大化未来路径价值
-
不能只看当前,必须看整体树状结构
动作项:
绘制自己常见局面的决策树模型。
5. 风险偏好(Risk Preference)
定义:
个体面对风险的心理倾向。
落地判断:
-
有人偏向保守,有人偏向冒险
-
同样局面,不同性格做出不同策略
-
风险偏好影响长期行为表现
动作项:
记录自己在“关键抉择”下的情绪与行为。
6. 认知偏差(Cognitive Bias)
定义:
在判断与决策中出现的系统性心理错误。
常见偏差:
-
确认偏误
-
损失厌恶
-
锚定偏差
-
赌徒谬误
-
过度自信
落地判断:
理性决策常被感性冲动取代。
动作项:
为自己建立“偏差检查表”。
7. 信息价值(Value of Information, VoI)
定义:
信息对决策质量提升的实际价值。
落地判断:
-
有些行动能获得大量信息
-
有些行动会泄露自己的信息
-
VoI 决定策略结构
动作项:
为各种行动标记“信息价值高/中/低”。
8. 随机过程(Stochastic Process)
定义:
随时间推移由随机变量主导的过程。
落地判断:
-
每张牌的出现是随机过程的一部分
-
模型可分析随机性,但不能预测下一张牌
-
短期波动无法避免
动作项:
模拟不同数量局次下的收益曲线。
9. 策略混合(Mixed Strategy)
定义:
以一定概率执行多种策略,以避免被对手利用。
落地判断:
-
固定打法最容易被识别
-
纳什均衡需要混合策略
-
AI 通过混合策略达成近均衡结构
动作项:
在特定决策节点加入概率控制。
10. 利用率(Exploitability)
定义:
某策略被对手分析并利用的可能性与程度。
落地判断:
-
越可预测,越容易被压制
-
最优策略旨在降低可利用程度
-
非均衡策略往往“短期好看,长期崩塌”
动作项:
从对手视角分析:我是否容易被预判?
方法步骤
本章构建科学研究德扑的系统方法,不涉及任何赌博技巧或胜率提升行为。
步骤一:构建德州扑克的概率结构模型
德扑的数学核心是 组合数学(Combinatorics)。
1. 起手牌组合数
总共有:
C522=1,326C_{52}^{2} = 1,326
其中仅 169 种为不考虑花色的“起手类型”。
2. 公共牌组合数巨大
翻牌(3 张):
C503=19,600C_{50}^{3} = 19,600
转牌(1 张):
C471=47C_{47}^{1} = 47
河牌(1 张):
C461=46C_{46}^{1} = 46
整个德扑的样本空间是一个接近天文数字的组合体系。
动作项:
用软件或表格建立自己的组合矩阵。
步骤二:建立期望值模型(EV Model)
期望值公式:
EV=P(win)×V(win)−P(loss)×V(loss)EV = P(win) \times V(win) – P(loss) \times V(loss)
其中变量代表:
-
P(win)P(win):胜率
-
V(win)V(win):赢得的数值
-
P(loss)P(loss):失败概率
-
V(loss)V(loss):损失数值
示例(纯数学示范):
若:
-
胜率 0.4
-
赢 +10
-
败 -6
则:
EV=0.4×10−0.6×6=+0.4EV = 0.4 × 10 – 0.6 × 6 = +0.4
说明:即便胜率不到一半,长期仍具正期望。
边界条件:
-
EV 只能基于长期模型,不代表短期
-
EV 对样本数量敏感,局数太少偏差极大
失败示例:
-
仅用 1 次或数次结果来评估 EV
-
用直觉替代概率估计
动作项:
尝试建立常见决策的简单 EV 表格。
步骤三:用决策树分析策略影响
德扑是一款 多阶段决策游戏。
从起手到河牌,每一步都存在分叉:
每一个节点的路径影响后续结构。
动作项:
绘制 1 手牌的决策树,理解复杂度。
步骤四:构建“不完全信息推断”模型(Bayesian Model)
贝叶斯更新公式:
P(A∣B)=P(B∣A)⋅P(A)P(B)P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)}
意义:
-
初始假设(对手范围)是 先验分布
-
公共牌与行为导致 条件概率更新
-
最终得到对手牌可能性的 后验分布
动作项:
为不同对手建立“范围推断矩阵”。
步骤五:理解纳什均衡对策略的意义
纳什均衡不代表“最强策略”,而是:
在无人知道对手策略的前提下,任何人都无法单方面通过改变策略获得更高收益。
学术意义:
-
均衡策略最安全
-
固定策略最容易被利用
动作项:
观察自己的行为模式是否固定、可预测。
步骤六:构建行为经济学分析体系
德扑中的人类行为偏差是可量化的科研对象。
常见偏差举例:
1. 损失厌恶(Loss Aversion)
人对损失的痛苦大约是收益满足的 2 倍。
2. 锚定偏差(Anchoring Bias)
无关信息影响最终判断。
3. 过度自信(Overconfidence)
错估自己的判断能力。
4. 赌徒谬误(Gambler’s Fallacy)
认为随机事件会“纠正”。
动作项:
在关键决策前进行“偏差自检”。
步骤七:分析“信息价值”(VoI)
不同行动的“信息价值”不同:
-
加注 → 信息价值高
-
过牌 → 信息价值低但隐藏信息
-
跟注 → 价值中等但常被误解
VoI 影响策略结构。
动作项:
在每个行动标记“信息价值等级”。
系统化案例(全部重写,纯学术模型)
以下案例完全为数学与行为分析模型,不涉及赌博技巧。
案例一:范围推断在不完全信息博弈中的作用
场景(虚构科学模型):
-
对手在翻牌前进行一次中等加注
-
公共牌出现两个高牌
-
对手在翻牌前不行动
-
你需要推断范围
数学意义:
-
范围比猜测单一牌更可控
-
范围可被贝叶斯更新
-
决策更稳定
动作项:
在笔记本中练习“范围构建→范围缩小→范围更新”。
案例二:随机过程导致短期波动
模拟:
-
弱策略在 20 局内可能超越强策略
-
强策略在 10,000 局内必然领先
随机过程(短期) vs 期望值(长期)
动作项:
建立随机模拟器,比较短期与长期差异。
案例三:损失厌恶导致的错误判断
实验数据:
-
多数人在面对损失时会过度反应
-
长期导致决策偏离数学最优
动作项:
为自己的情绪行为做量化记录。
案例四:纳什均衡的现实意义
假设双方都使用接近均衡策略:
-
策略不可被利用
-
收益波动较小
-
行为模式透明但不弱点化
动作项:
尝试用“混合策略”处理不确定局面。
案例五:信息价值导致的策略差异
某些行动不为直接收益,而为:
-
获得隐藏信息
-
控制决策节奏
-
构建心理压力
-
重设对手范围
动作项:
为不同行动编写“信息影响档案”。
常见误区与纠偏
误区一:德扑是运气游戏
纠偏:
它是一个信息不完全博弈,数学结构非常复杂。
误区二:对手动作总是真实信号
纠偏:
许多动作由策略混合导致,不代表真实牌面。
误区三:短期输赢反映策略好坏
纠偏:
短期被随机性主导。
误区四:推断应该集中在“对手具体牌”
纠偏:
范围推断远优于单牌猜测。
误区五:某种固定打法可以长期有效
纠偏:
固定策略最容易被利用(Exploitability 高)。
工具与清单
1. 概率矩阵(起手牌、成牌、公共牌结构)
2. 决策树绘图模板
3. EV 参数化工具
4. 范围推断表格
5. 行为偏差自检表
6. 信息价值等级表
结论
德州扑克不是赌博工具,而是一个多维度的科学模型:
-
它是数学的:组合、概率、期望
-
它是心理学的:偏差、情绪、决策
-
它是经济学的:风险偏好与效用函数
-
它是博弈论的:信息不对称、均衡结构
-
它是计算机科学的:AI 学习、对抗系统
学习德州扑克的科学结构,有助于提升:
-
理性判断
-
风险处理能力
-
结构化思维
-
模型分析能力
-
复杂环境中的决策能力
它是一面镜子,映照人类如何在不确定世界中做选择。
FAQ(5–10问)
1. 德扑是如何成为科学研究的模型?
因为它同时具备随机性、对抗性和信息不完全性。
2. 概率与直觉的冲突常见吗?
非常常见,人类直觉不擅长处理复杂概率。
3. 为什么范围推断比猜测单牌更科学?
因为现实中无法知道对手底牌,只能推断概率结构。
4. 随机性是否会掩盖策略优劣?
短期会,长期不会。
5. 行为偏差如何影响决策?
它会导致情绪取代逻辑,从而偏离模型最优路径。
6. 为什么纳什均衡重要?
它保证策略不可被利用。
7. 信息价值为什么影响策略?
因为策略不是单纯为了赢,而是为了优化未来决策质量。
8. 德扑是否可以完全求解?
目前尚不行,但部分形式可以逼近均衡。
9. 决策树是否能完全描述德扑?
理论上可以,现实中规模巨大但可简化分析。
10. 德扑能训练哪些能力?
风险认知、概率思维、心理分析、逻辑推断。
术语表
-
不完全信息博弈:信息部分隐藏
-
概率分布:事件结果的比例结构
-
期望值:长期平均数学收益
-
决策树:行动后可能结果的树状结构
-
风险偏好:面对风险的态度
-
认知偏差:心理导致的判断错误
-
随机过程:由随机变量主导的过程
-
信息价值:信息改善决策的价值
-
策略混合:用概率混合执行策略
-
利用率:策略能被对手利用的程度



