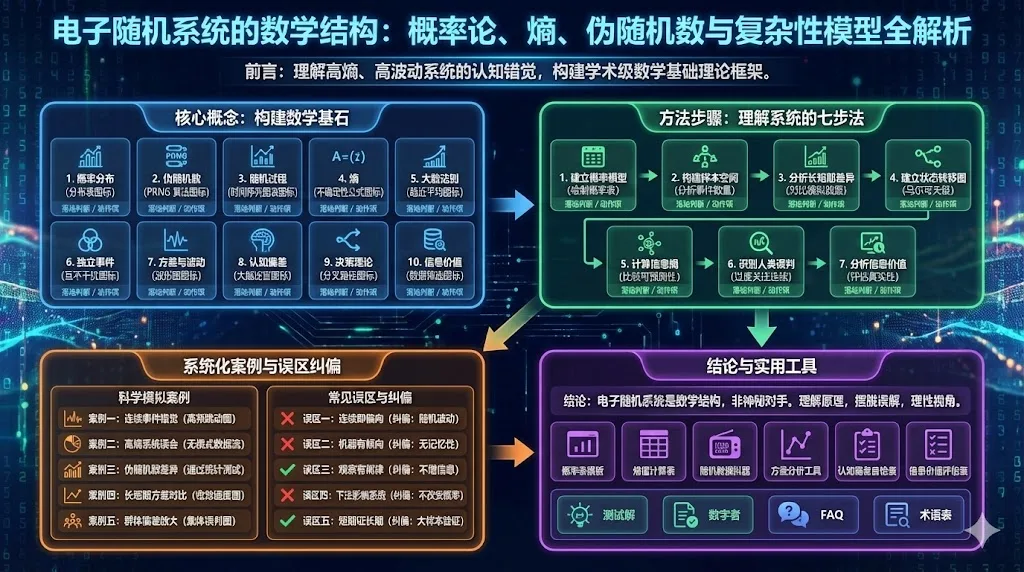
前言
在当代数字娱乐设备中,电子随机系统已成为普遍存在的基础结构。从简单的掷骰模拟器到大型复杂的娱乐装置,再到移动端的随机数机制,它们在技术与数学层面构成了一个高度精密的模型群。许多人在面对这些系统时,往往会产生“它好像有眼睛”“它懂得针对人”“它有自己的偏好”等误解,这些现象并非源自机器,而是人类面对高熵、高波动系统时的认知错觉。
电子随机系统本质上是:
- 概率论的应用实例
- 伪随机算法的数学呈现
- 信息熵高度集中的系统
- 人类行为经济学的实验平台
- 复杂系统领域中的混沌模型
本篇文章旨在构建一个学术级、系统化、结构完整的理论框架,全面解析电子随机系统的数学基础、算法结构、行为表现、误解来源以及系统复杂性。
文章将通过以下维度进行系统化分析:
- 概念定义
- 公式推导
- 案例模拟
- 行为偏差
- 信息论
- 随机过程
帮助读者理解该类系统的真正运行原理。
第一章:十大核心数学概念
每个概念包含:定义 + 落地判断 + 动作项
1. 概率分布(Probability Distribution)
:
描述随机事件所有可能结果及其出现概率的数学结构。
落地判断:
- 掷骰是均匀分布
- PRNG 输出是近似均匀分布
- 长期概率可测,短期波动巨大
动作项:
为你生活中的任意随机现象构建概率分布表。
2. 伪随机数(Pseudo-Random Numbers, PRNG)
定义:
由算法生成,通过数学方法伪装成“不可预测”的数字序列。
落地判断:
- PRNG 不是“随便生成”
- 是严格遵循数学规则的近似随机
- 现代算法难以被预测或干预
动作项:
尝试用 Python 生成一个 PRNG 序列并分析分布。
3. 随机过程(Stochastic Process)
定义:
由时间驱动,随时间变化的随机变量序列。
落地判断:
- 时间越长,分布越均匀
- 短期差异并不能说明偏差
- 随机过程可通过模型模拟
动作项:
收集任意 100 个连续随机值并绘制图表观察波动。
4. 熵(Entropy)
定义:
系统不确定性或混乱程度的度量。
公式:
H=−∑pilogpi
落地判断:
- 随机系统的熵非常高
- 高熵 → 难以预测
- 越随机的系统越难看出结构
动作项:
比较不同事件(如抛硬币、骰子、手机随机函数)的熵值。
5. 大数法则(Law of Large Numbers)
定义:
重复次数增加,实验平均值趋近理论概率。
落地判断:
- 20 次掷骰 → 混乱
- 20000 次掷骰 → 接近均匀
- 长期趋势稳定,短期波动巨大
动作项:
模拟一次 100 次试验与 5000 次试验的差异。
6. 独立事件(Independent Events)
定义:
一个事件的结果不会影响下一次事件结果。
落地判断:
- 每一轮随机过程互不相关
- “连续出现”不代表机器偏好
- “该出现的还没出现”是错误认知
动作项:
记录自己对连续事件的判断偏差。
7. 方差(Variance)与波动(Volatility)
定义:
描述数据偏离平均值的程度。
方差公式:
Var(X)=E[(X−μ)2]
落地判断:
- 高波动会让人感觉“系统不正常”
- 有些事件本质上波动极高
- 高方差让人产生“错觉模式”
动作项:
计算一组随机数据的方差,理解波动性。
8. 认知偏差(Cognitive Bias)
定义:
人在判断概率时出现的系统性错误。
常见类型:
- 赌徒谬
- 锚定偏差
- 过度拟合
- 自信
- 损失厌恶
落地判断:
- 人类擅长理解真正的随机
- 情绪常超越理性
- 模式识别本能导致误解
动作项:
记录自己在随机事件中的情绪变化。
9. 决策理论(Decision Theory)
定义:
研究人在不确定环境下如何选择的学科。
落地判断:
- 决策不是预测结果
-选择“更符合自身目标的选项” - 风险偏好影响行为
动作项:
为任意两种选择建立决策树。
10. 信息价值(Value of Information, VoI)
定义:
新信息能提升决策质量的程度。
落地判断:
- 在独立事件中,观察不提升信息价值
- 高频随机系统的信息价值极低
- 认知偏差常会误把无意义信息当做线索
动作项:
从你所感“似乎有用的信息”中划掉那些其实对结果无影响的部分。
第二章:理解电子随机七步骤方法体系
以下提供一个理解电子随机系统的七步骤方法体系,完全用于数学认知,无实战用途。
步骤一:建立系统的概率模型
任何电子随机系统本质上都可描述成:
- 一个有限或无限样本空间
一个固定概率分布模型 - 一个状态转移过程
动作项:
为你观察到的系统绘制概率。
步骤二:构建样本空间并分析事件数量
例如掷三个骰子的样本空间:
63=216
其中不同事件类别的数量差异巨大:
- 三骰不同
- 两骰相同
- 三骰相同(围骰)
理解样本空间有助于分析事件概率结构。
步骤三:分析短期与长期行为差异
- 短期行为 → 高方差、混乱
- 长期行为 → 稳定、可统计
动作项:
模拟一组短期数据与一组长期数据并对比。
步骤四:建立随机过程的状态转移图(马尔可夫链)
定义状态:
- S0:未出现特殊结果
- S1:出现少见事件
- S2:连续出现事件
- ……
状态转移矩阵可描述系统动态。
步骤五:计算信息熵并比较系统可预测性
熵越高:
- 越不可预测
- 越容易让人误解为“有规律”
这是因为人类无法直观处理高熵数据。
步骤六:识别人类对随机性的误判来源
- 过度关注连续事件
- 误以为随机会“自己”
- 情绪化解读短期偏差
- 误把噪声信号
步骤七:分析信息价值是否真实有效
许多人会把如下信息误认为“有意义”:
- 某数字“很久没出现”
- 某“似乎在重复”
- 某人“押了大注”
- 设备“刚刚连续开了多少次某结果”
这些都属于 零信息价值。
第三章:系统化案例分析
以下案例全部为科学模拟,并无涉及实际下注行为。
案例一:连续事件的错觉(赌徒谬误)
模拟一个公平随机系统:
连续出现 5 次极少见事件的概率不低于:
(16)5
该概率虽低,但在大量实验中会频繁出现,人类却会误判为“有异常”。
案例二:高熵系统为何容易引发误会
模拟10000 个随机数:
- 图形呈高频跳动- 看似有模式
- 实际无任何可预测结构
这是高熵导致的模式错觉。
案例三:伪随机数与真实随机的差异
一个优质 PRNG 的序列:
- 通过统计测试
- 与真实随机无法区分
- 短期同样混乱
这解释了为何电子设备的“怪异结果”本质上是正常表现。
案例四:长短期方差差异的对比
- 短期(30 次):方差高、结果偏离概率大
- 长期(3000 次):方差相对收敛
数学推导显示:
\text{方差收敛速度} \propto \frac{1n}
案例五:群体行为如何放大随机误判
实验显示:
当多人同时观察高随机系统时,他们的偏差会通过模仿强化,最终产生集体错误判断,如:
- “它现在偏向某结果”
- “它针对某些人”
这在行为经济学中被称为 集体偏差放大效应。
第四章:常见误区与科学纠偏
| 误区 | 纠偏 |
|---|---|
| 误区一:连续出现说明系统有偏向 | 连续出现本质是方差造成的随机波动。 |
| 误区二:机器会“改变倾向” | 独立事件无记忆性。 |
| 误区:观察能发现规律 | 随机系统中观察不增加信息。 |
| 误区四:有人注大注会影响系统 | 电子系统不根据行为输入改变概率。 |
| 误区五:短期结果证明长期趋势 | 必须用大样本验证趋势。 |
第五章:实用工具与清单
工具清单
- 概率表模板
- 熵值计算表
- 随机数模拟器
- 方差分析工具
- 认知偏差自检表
- 信息价值评估表
结论
电子随机系统“神秘的对手”,也不会“针对某些人”,它是:
- 概率论
- 熵
- 随机过程
- 伪随机算法
- 统计学
- 行为经济学
共同构成的结构。
理解这些原理可以帮助人们摆脱对随机系统的误解,学会用科学的方式理解不确定性,并在生活中的各种随机现象中保持理性视角。
FAQ(十问)
-
随机系统可预测吗?
长期分布可预测,单次结果不可预测。 -
为什么系统会连续出现异常?
这是高方差自然表现。 -
伪随机能被破解吗?
现代 PRNG 在正常环境下难以破解。 -
观察是否能增加预测力?
不能,独立事件无记忆。 -
熵高意味着什么?
表示系统不可预测性强。 -
为什么人类容易误解随机?
认知偏差与本能模式识别导致。 -
随机过程是否有“情绪”?
没有,情绪来自观察者。 -
长期稳定是否意味着公平?
长期概率趋近数学结构,与情绪无关。 -
PRNG 和真随机区别大吗?
对大多数应用来说几乎不可区分。
10 为什么越多人参与越容易误判?
因为集体偏差会在群体中扩散并增强。
术语表
| 术语 | 定义 |
|---|---|
| 概率分布 | 随机事件所有可能结果及其概率的数学结构 |
| 伪随机数 | 由算法生成的近似随机数字序列 |
| 熵 | 系统不确定性的度量 |
| 大数法则 | 重复次数增加,平均值趋近理论概率 |
| 方差 | 数据偏离平均值的程度 |
| 随机过程 | 随时间变化的随机变量序列 |
| 认知偏差 | 人判断概率时的系统性错误 |
| 独立事件 | 互不影响的事件 |
| 决策理论 | 研究不确定环境下如何选择的学科 |
| 信息价值 | 信息提升决策质量的程度 |



